
Enigma’s Next Frontier: Unlocking UAP Data with Machine Learning and Retrieval-Augmented Generation (RAG)
At Enigma, we are continually pushing the boundaries of technology to glean insights into Unidentified Aerial Phenomena (UAP). With over 25,000 user-submitted UAP sightings submitted to us, we’ve created the most robust, queryable dataset in the world, and are grateful to our loyal skywatching community. We are now at a stage where we are expanding our analytics and beginning to harness artificial intelligence to unlock patterns among this trove of witness sightings.
Our first small-scale use of AI tools was in integrating Meta’s Llama3, which we use to automatically generate concise and personalized titles for each witness’ sighting report. We are also diving head first into object detection and identification in video submissions — more to come on that soon. Below we are sharing more about our recent progress in the way we use AI to retrieve, interpret, and respond to this wealth of sightings data. Specifically, we will elaborate on how we are tapping into the power of Retrieval-Augmented Generation (RAG).
A Retrieval-Augmented Generation (RAG) system is an advanced AI approach that combines retrieval and generation components to produce accurate, context-aware responses. Unlike standard language models, which generate responses based only on their pre-existing training data, a RAG system is augmented by retrieving specific information from an external dataset — in our case, the Enigma UAP database. This retrieval step enhances the model’s responses, allowing it to incorporate fresh, relevant details from the database into its answers, making them more precise and directly informed by the latest data.
A RAG system is composed of the following core elements (Fig. 1):
1. Retrieval Component:
The retrieval component locates relevant documents or data entries from a large dataset based on the user’s query. To enable flexible, context-driven search, each document in the dataset is transformed into a mathematical representation, or “embedding,” capturing the document’s semantic content. A vector database, like Chroma or Pinecone, stores these embeddings, allowing the retrieval component to find documents with embeddings most similar to the query’s embedding. This way, the system can locate relevant information based on semantic proximity even if the query doesn’t use exact keywords. A traditional keyword search for “winter sightings,” for instance, may miss data described as occurring during a “snowy season” or “cold months.” By contrast, RAG’s semantic understanding enables it to bridge these language gaps, allowing users to query with natural phrases and retrieve nuanced results.
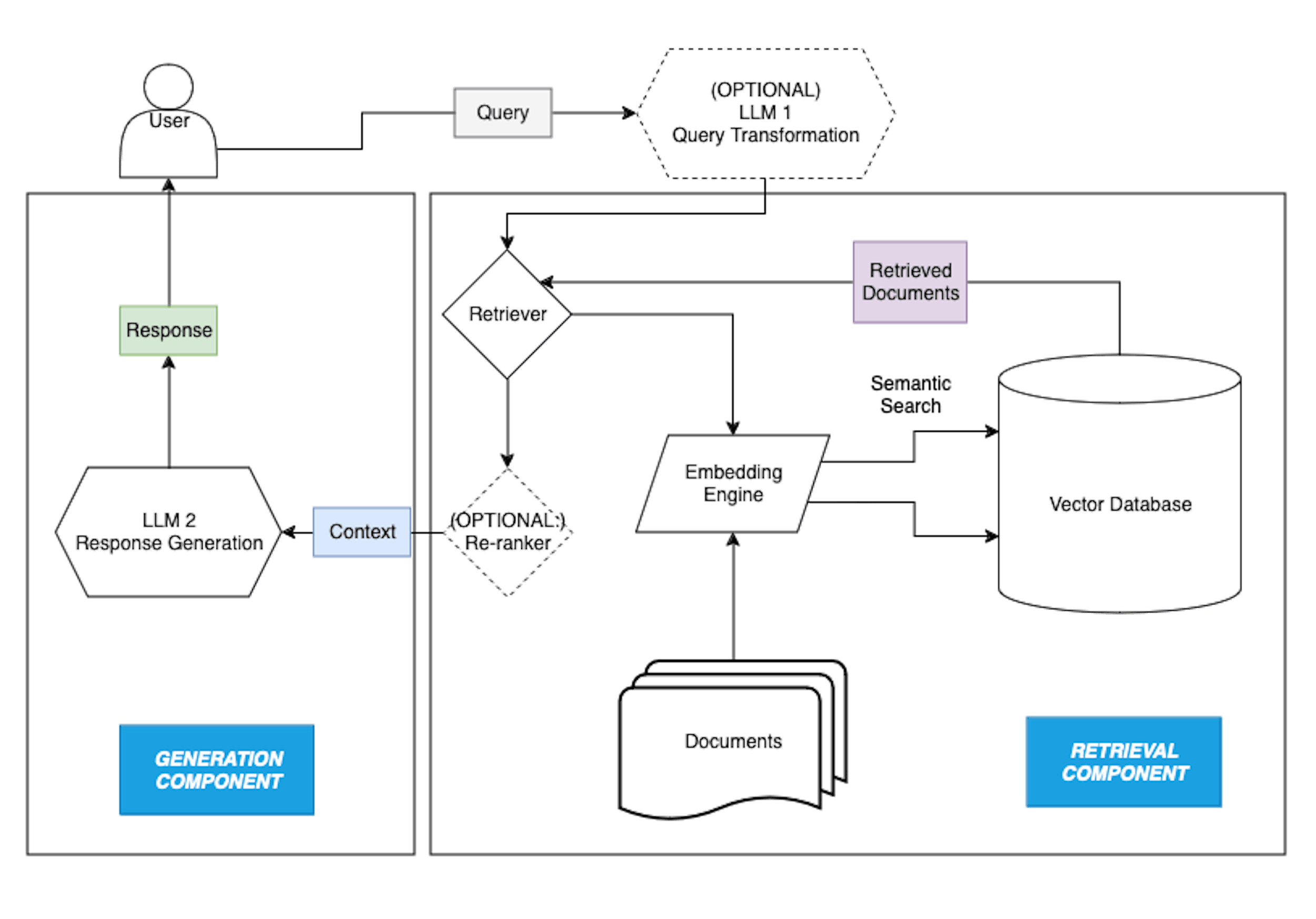
Figure 1: The core components of a RAG system. In the retrieval component, an embedding engine maps queries and documents to embeddings, which are stored in a vector database. The retriever retrieves documents from this database based on semantic similarities (and/or applied structured filters). The retrieved documents are passed to the generation component, which uses an LLM to generate a coherent, natural language response based on the retrieved documents.
2. Generation Component:
After the retrieval component gathers relevant documents, the generation component, typically a language model like GPT-4, synthesizes this data into a natural language response. The generation component uses retrieved information to generate answers that are both precise and fluent, producing responses that feel natural while being grounded in actual retrieved content. These core components enable RAG to handle unstructured data and complex queries, producing responses with a depth and precision far beyond traditional keyword search methods.
While RAG is often text-based, it can be extended to multi-modal applications that involve other data types, such as video, audio, and images. We have also explored this exciting aspect of RAG. In Enigma’s multi-modal RAG proof of concept, additional models handle these various media types: Blip2 processes video frames for image captioning, Whisper transcribes audio, and Llama integrates these elements into a cohesive summary. This multi-modal capability allows RAG to retrieve, interpret, and synthesize data across multiple formats, expanding its usefulness for complex datasets.
To fully illustrate the potential of RAG to revolutionize UAP research, we completed two powerful Proofs of Concept (POCs).
POC 1 - Single-Mode RAG (Text-Based Retrieval):
This POC is all about enhancing how we retrieve relevant sightings using natural language. Traditional structured queries rely on exact terms or filters, which limit search flexibility. Our Single-Mode RAG system, however, combines both the precision of filters and the flexibility of semantic searches by interpreting and translating natural language queries into actionable filters, and applying these filters along with the semantic similarity search. We are well positioned to implement this filtering since we readily collect a wide array of structured data fields when we ask an Enigma user to submit his/her sighting. These fields include the timestamp, the number of witnesses, and shape of the observed objects, to name a few. The query-to-filter mapping is realized through the use of self-query transformation, a functionality that interprets user queries into specific filters and conditions, as supported by the specific vector database employed (in this POC, Chroma) and our structured data schema. For example, a query about “sightings involving triangular-shaped objects between 2020 and 2021” could be transformed to include relevant date ranges (timestamp >= “2020-01-01 00:00:00” AND timestamp <= “2022-01-01 00:00:00”) and shape (=“triangle”) conditions. This transformation enhances retrieval accuracy, allowing users to make more nuanced searches without any prior knowledge of our data schema and filter options.
To benchmark the effectiveness of this system, we measured the retrieval accuracy by coming up with a set of 50 queries and identifying the set of documents that would correctly answer each query. We then assessed whether the retrieved documents matched the documents we had previously identified on a query-by-query basis, enabling us to measure the precision and recall. The precision and recall rates for this POC stand at ~75% and ~70%, respectively — strong indicators of the system’s ability to retrieve relevant reports accurately.
POC 2 - Multi-Modal RAG (Video/Audio Summarization):
Expanding beyond text, our second POC tackles the unique challenge of integrating multimedia content — specifically video and audio submissions. This POC combines frames from videos and audio clips to generate a comprehensive summary of UAP events. We selected models like Blip2 for image captioning, Whisper for audio transcription, and Llama3 for summarization, each chosen for its ability to process complex data in a specific domain accurately.
The accuracy metrics for this multi-modal POC are as follows:
- Frame Captioning (Blip2): Achieved a score of 53.04/100, effectively identifying certain objects but occasionally misidentifying small or distant ones. For instance, a drone swarm at a distance might be labeled ambiguously due to low resolution.
- Audio Transcription (Whisper): Scored 79.57/100, showing solid performance in transcribing spoken descriptions. However, background noises occasionally led to hallucinations, where the model incorrectly interpreted sounds as speech. A de-noising pre-processing step is needed to mitigate this.
- Summarization (Llama3): Scored 77.39/100, this task involves integrating the captions and transcriptions into a coherent summary. Notice that even when frame captions were partially inaccurate, the summarization model could still usually accurately generate meaningful descriptions of the UAP video content.
Together, these individual POCs mark a foundational step. Ultimately we intend to bring them together to form a unified RAG platform that can handle text, video, and audio data — giving us a multi-layered approach to analyze UAP events like never before (Fig. 2).
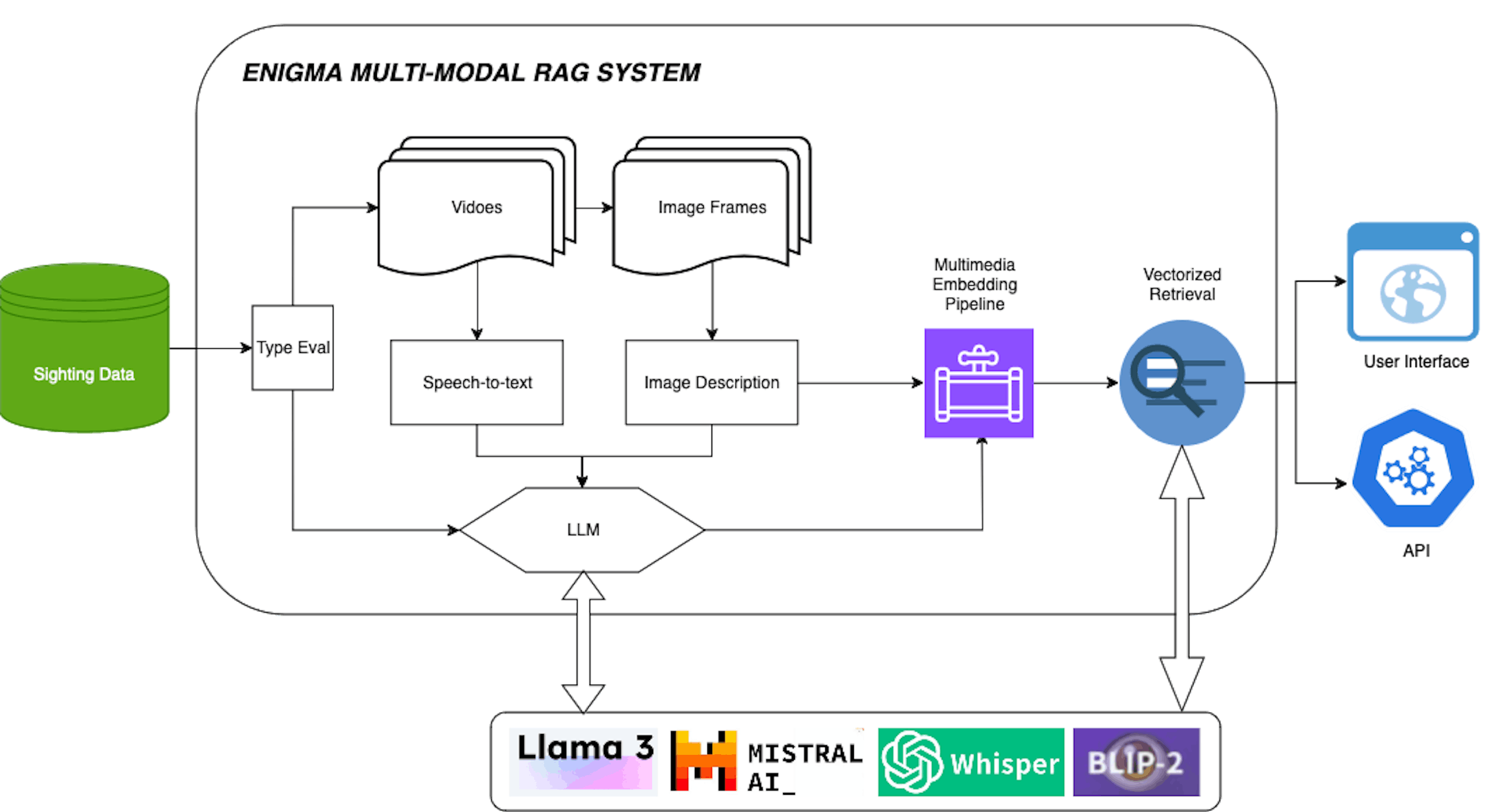
Figure 2: The multi-modal RAG pipeline with swappable LLMs integrated with Enigma multimedia datasets. The response can be delivered to user interfaces (such as our app), or through API access.
The end goal is ambitious but clear: to create a public-facing RAG system that enables anyone to query and analyze our ever-growing UAP database. Imagine entering queries that go beyond simple keywords to uncover deeper, more contextual connections within our data. Whether you’re a researcher looking to track certain UAP behaviors, a hobbyist interested in regional trends, or simply curious about the unknown, Enigma’s RAG platform will make the data work for you. Fig. 3 is a mock-up of a user interface that we may build with the multi-modal RAG system.
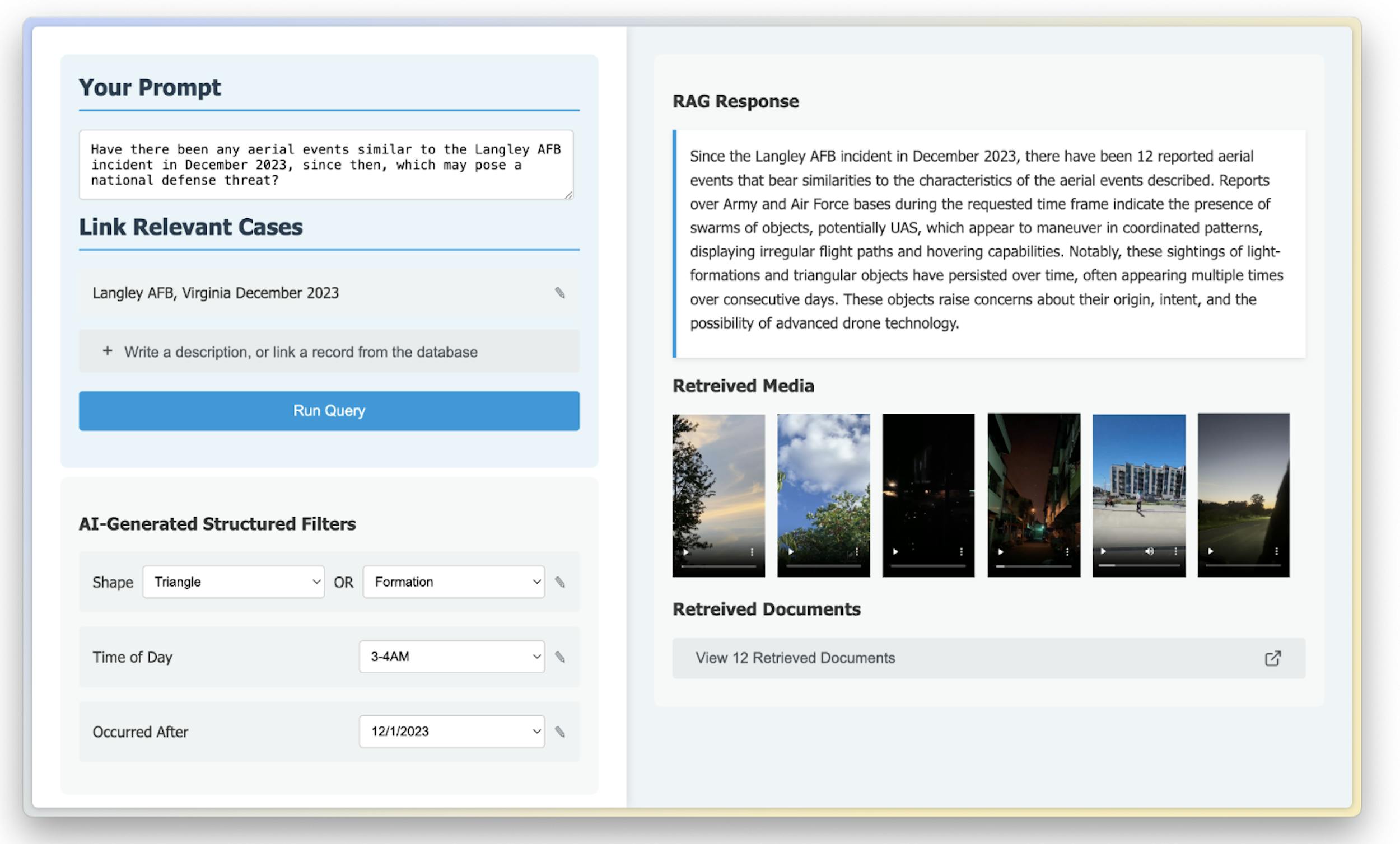
Figure 3: In this mock-up interface, the user enters a query prompt. The system allows the user to adjust generated structured filters, and then returns a response along with relevant media contents. In this example, a user is interested in sightings that may pose national security threats similar to the Langley AFB UAP swarming in 2023.
In this evolving journey, we aim to develop tools that leverage RAG to bring more transparency, understanding, and ease of access to the world of UAP research. Enigma’s RAG integration represents just the beginning of what’s possible as we explore new technologies.
Thank you for being part of Enigma’s mission to unlock the unknown. We are grateful to you for forming our skywatching network – continue to be vigilant about the skies, and submit your sighting today online or on our free app. Happy skywatching!